
来自:http://fbi.taobao.org/?p=51
整体的类图在API文档上已经有了详细的说明:http://netty.io/docs/stable/api/
基本上的类都是继承自AbstractChannelBuffer,其他的都是接口或者工厂类,另外也有部分会实现WrappedChannelBuffer接口。
这里使用了典型的模板模式,AbstractChannelBuffer中会统一负责实现read和write的时候改变readIndex和writeIndex的逻辑,而具体的子类则实现底层的数据拷贝逻辑,比如HeapChannelBuffer和CompositeChannelBuffer(封装了多个Buffer的访问逻辑)
ChannelBuffer和ByteBuffer
ByteBuffer是nio中提供的缓冲区,他设计采用position、limit、capacity、mark等4个属性来表示一个缓冲区;另外还有视图的功能;

如果是非直接缓冲区,那么使用wrap或者allocate创建的都是HeapByteBuffer类型,看了下源码,主要是使用System.arraycopy来作为高效的字节拷贝为get、put、compact等基础操作提供支持。使用ByteBuffer唯一不方便的感觉就是flip()方法,因为只有一个position的设计,在write之后必须调用flip才能调用read。
ChannelBuffer则没有这个问题,API文档上说,相对于ByteBuffer有以下优势:
1.You can define your buffer type if necessary.
2.Transparent zero copy is achieved by built-in composite buffer type.
3.A dynamic buffer type is provided out-of-the-box, whose capacity is expanded on demand, just ike StringBuffer.
4.There’s no need to call the flip() method anymore.
5.It is often faster than ByteBuffer.
3和4都是能够直接带来方便的地方
ChannelBuffer不再是position和limit的架构,而是有以下几个属性
- private int readerIndex;
- private int writerIndex;
- private int markedReaderIndex;
- private int markedWriterIndex;
也就是这样

readerIndex和writerIndex都是一开始都是0,随着数据的写入writerIndex会增加,读取数据会使readerIndex增加,但是他不会超过writerIndx,在读取之后,0-readerIndex的就被视为discard的.调用discardReadBytes方法,可以释放这部分空间,他的作用类似ByeBuffer的compact方法;
读和写的时候Index是分开的,因此也就没必要再每次读完以后调用flip方法,另外还有indexOf、bytesBefore等一些方便的方法;DynamicBuffer他的内部还是单独的ChannelBuffer,只是他封装了自动扩容的功能,他会在所以write含义的方法之前检查是否有足够的容量,不足则扩容。
- public class DynamicChannelBuffer extends AbstractChannelBuffer {
- private final ChannelBufferFactory factory;
- private final ByteOrder endianness;
- private ChannelBuffer buffer;
- ……
- }
关于第2点设计的类主要是CompositeChannelBuffer,如果想将多个Buffer拼成一个,那在ByteBuffer中要么创建一个更大的Buffer然后拷贝,或者在操作中将多个Buffer依次进行IO,但是Netty的设计者说明明应该是一个,硬要用两个表示,很不直观
ByteBuffer[] message = new ByteBuffer[] { header, body };
因此在ChannelBuffer中就设计了CompositeChannelBuffer,他接收多个ChannelBuffer为参数,在内部抽象成一个大的Buffer,判断应该用哪个buffer,比如head、foot长度都10,你要get(11),那么他会自动使用foot,也就是说原来要自己做的事情,都抽象好了,用统一的ChannelBuffer表示。
第1点还没用过,第5点就存在一些疑问了,it is ofen faster than ByteBuffer,我想它大概指的是里面一些操作吧,但是实际上在需要IO底层毕竟还是只接受ByteBuffer,势必会有两者之间的转换,这个个人认为并不会fast。
WrappedChannelBuffer接口
另外实现WrappedChannelBuffer接口的类,则都是属于装饰了,ReadOnlyChannelBuffer将原有的write性质的方法都装饰没了,DuplicatedChannelBuffer则是和原有的Buffer共享数据,各自拥有readIndex和writeIndex。
关于ChannelBuffer的创建
关于创建,从类图上看,应该是用了工厂方法模式,当然估计用起来不是那么爽,每次都new个Factory再去创建,估计觉得写起来实在不便,所以还是用ChannelBuffers创建,个人觉得设计模式是个好东西,但是他应该是某些场合+某些模式的一个良好组合,也就是说只有在合适的常见用合适的设计模式才会有好的效果,如果不是很理解的话,那就“普通”一些写吧
Netty实现封装实现了自己的一套ByteBuffer系统,这个ByteBuffer系统对外统一的接口就是ChannelBuffer,这个接口从整体上来说定义了两类方法,一种是类似getXXX(int index…),setXXX(int index…)需要指定开始操作buffer的起始位置,简单点来说就是直接操作底层buffer,并不用到Netty特有的高可重用性buffer特性,所以Netty内部对于这类方法调用非常少,另外一种是类似readXXX(),writeXXX()不需要指定位置的buffer操作,这类方法实现放在了AbstractChannelBuffer,其主要的特性就是维持buffer的位置信息,包括readerIndex,writerIndex,以及回溯作用的markedReaderIndex和markedWriterIndex,当用户调用readXXX()或者writeXXX()方法时,AbstractChannelBuffer会根据维护的readerIndex,writerIndex计算出读取位置,然后调用继承自己的ChannelBuffer的getXXX(int index…)或者setXXX(int index…)方法返回结果,这类方法在Netty内部被大量调用,因为这个特性最大的好处就是很方便地重用buffer而不必去费心费力维护index或者新建大量的ByteBuffer。
另外WrappedChannelBuffer接口提供的是对ChannelBuffer的代理,他的用途说白了就是重用底层buffer,但是会转换一些buffer的角色,比如原本是读写皆可 ,wrap成ReadOnlyChannelBuffer,那么整个buffer只能使用readXXX()或者getXXX()方法,也就是只读,然后底层的buffer还是原来那个,再如一个已经进行过读写的ChannelBuffer被wrap成TruncatedChannelBuffer,那么新的buffer将会忽略掉被wrap的buffer内数据,并且可以指定新的writeIndex,相当于slice功能。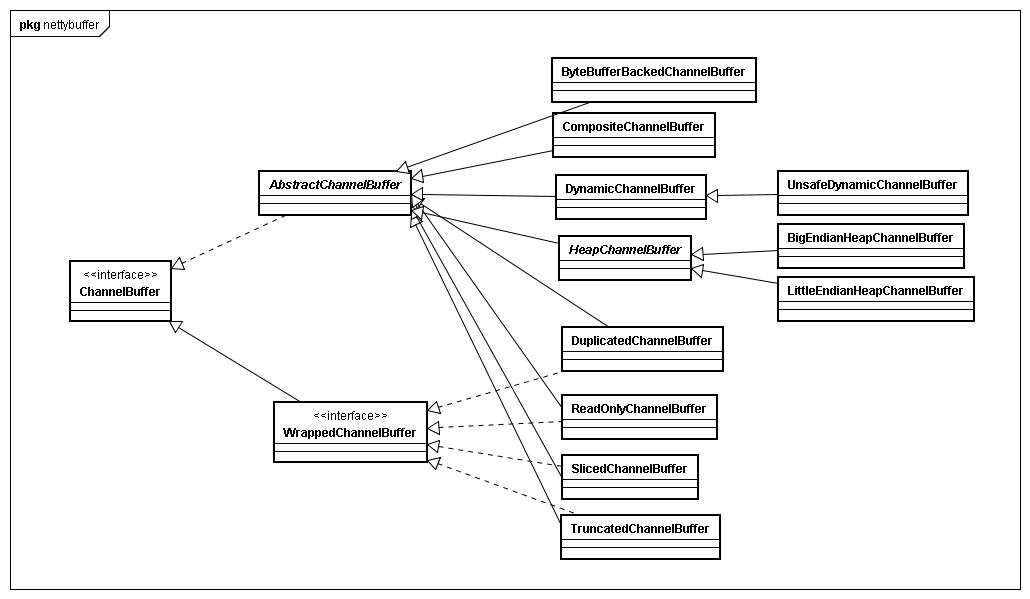
3、 buffer
org.jboss.netty.buffer包的接口及类的结构图如下:
该包核心的接口是ChannelBuffer和ChannelBufferFactory,下面予以简要的介绍。
Netty使用ChannelBuffer来存储并操作读写的网络数据。ChannelBuffer除了提供和ByteBuffer类似的方法,还 提供了 一些实用方法,具体可参考其API文档。
ChannelBuffer的实现类有多个,这里列举其中主要的几个:
1)HeapChannelBuffer:这是Netty读网络数据时默认使用的ChannelBuffer,这里的Heap就是Java堆的 意 思,因为 读SocketChannel的数据是要经过ByteBuffer的,而ByteBuffer实际操作的就是个byte数组,所以 ChannelBuffer的内部就包含了一个byte数组,使得ByteBuffer和ChannelBuffer之间的转换是零拷贝方式。根据网络字 节续的不同,HeapChannelBuffer又分为BigEndianHeapChannelBuffer和 LittleEndianHeapChannelBuffer,默认使用的是BigEndianHeapChannelBuffer。Netty在读网络 数据时使用的就是HeapChannelBuffer,HeapChannelBuffer是个大小固定的buffer,为了不至于分配的Buffer的 大小不太合适,Netty在分配Buffer时会参考上次请求需要的大小。
2)DynamicChannelBuffer:相比于HeapChannelBuffer,DynamicChannelBuffer可动态 自适 应大 小。对于在DecodeHandler中的写数据操作,在数据大小未知的情况下,通常使用DynamicChannelBuffer。
3)ByteBufferBackedChannelBuffer:这是directBuffer,直接封装了ByteBuffer的 directBuffer。
对于读写网络数据的buffer,分配策略有两种:1)通常出于简单考虑,直接分配固定大小的buffer,缺点是,对一些应用来说这个大小限 制有 时是不 合理的,并且如果buffer的上限很大也会有内存上的浪费。2)针对固定大小的buffer缺点,就引入动态buffer,动态buffer之于固定 buffer相当于List之于Array。
buffer的寄存策略常见的也有两种(其实是我知道的就限于此):1)在多线程(线程池) 模型下,每个线程维护自己的读写buffer,每次处理新的请求前清空buffer(或者在处理结束后清空),该请求的读写操作都需要在该线程中完成。 2)buffer和socket绑定而与线程无关。两种方法的目的都是为了重用buffer。
Netty对buffer的处理策略是:读 请求数据时,Netty首先读数据到新创建的固定大小的HeapChannelBuffer中,当HeapChannelBuffer满或者没有数据可读 时,调用handler来处理数据,这通常首先触发的是用户自定义的DecodeHandler,因为handler对象是和ChannelSocket 绑定的,所以在DecodeHandler里可以设置ChannelBuffer成员,当解析数据包发现数据不完整时就终止此次处理流程,等下次读事件触 发时接着上次的数据继续解析。就这个过程来说,和ChannelSocket绑定的DecodeHandler中的Buffer通常是动态的可重用 Buffer(DynamicChannelBuffer),而在NioWorker中读ChannelSocket中的数据的buffer是临时分配的 固定大小的HeapChannelBuffer,这个转换过程是有个字节拷贝行为的。
对ChannelBuffer的创建,Netty内部使用的是ChannelBufferFactory接口,具体的实现有 DirectChannelBufferFactory和HeapChannelBufferFactory。对于开发者创建 ChannelBuffer,可使用实用类ChannelBuffers中的工厂方法。
实例:
在学字符串消息收发的时候,已经提到过。ChannelBuffer是Netty中非常重要的概念。所有消息的收发都依赖于这个Buffer。我们通过Netty的官方的文档来了解一下,基于流的消息传递机制。
In a stream-based transport such as TCP/IP, received data is stored into a socket receive buffer.Unfortunately, the buffer of a stream-based transport is not a queue of packets but a queue of bytes. Itmeans, even if you sent two messages as two independent packets, an operating system will not treat themas two messages but as just a bunch of bytes. Therefore, there is no guarantee that what you read is exactlywhat your remote peer wrote. For example, let us assume that the TCP/IP stack of an operating system hasreceived three packets:+—–+—–+—–+| ABC | DEF | GHI |+—–+—–+—–+Because of this general property of a stream-based protocol, there's high chance of reading them in thefollowing fragmented form in your application:+—-+——-+—+—+| AB | CDEFG | H | I |+—-+——-+—+—+Therefore, a receiving part, regardless it is server-side or client-side, should defrag the received data into oneor more meaningful frames that could be easily understood by the application logic. In case of the exampleabove, the received data should be framed like the following:+—–+—–+—–+| ABC | DEF | GHI |+—–+—–+—–+
不知道您理解了没,简单翻译一下就是说。在TCP/IP这种基于流传递的协议中。他识别的不是你每一次发送来的消息,不是分包的。而是,只认识一个整体的流,即使分三次分别发送三段话:ABC、DEF、GHI。在传递的过程中,他就是一个具有整体长度的流。在读流的过程中,如果我一次读取的长度选择的不是三个,我可以收到类似AB、CDEFG、H、I这样的信息。这显然是我们不想看到的。所以说,在你写的消息收发的系统里,需要预先定义好这种解析机制,规定每帧(次)读取的长度。通过代码来理解一下:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
/** * @author lihzh
* @alia OneCoder
* @blog http://www.coderli.com
*/
public class ServerBufferHandler extends SimpleChannelHandler {
/**
* 用户接受客户端发来的消息,在有客户端消息到达时触发
*
* @author lihzh
* @alia OneCoder
*/
@Override
public void messageReceived(ChannelHandlerContext ctx, MessageEvent e) {
ChannelBuffer buffer = (ChannelBuffer) e.getMessage();
// 五位读取
while (buffer.readableBytes() >= 5) {
ChannelBuffer tempBuffer = buffer.readBytes(5);
System.out.println(tempBuffer.toString(Charset.defaultCharset()));
}
// 读取剩下的信息
System.out.println(buffer.toString(Charset.defaultCharset()));
}
} |
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
/** * @author lihzh
* @alia OneCoder
* @blog http://www.coderli.com
*/
public class ClientBufferHandler extends SimpleChannelHandler {
/**
* 当绑定到服务端的时候触发,给服务端发消息。
*
* @alia OneCoder
* @author lihzh
*/
@Override
public void channelConnected(ChannelHandlerContext ctx, ChannelStateEvent e) {
// 分段发送信息
sendMessageByFrame(e);
}
/**
* 将<b>"Hello, I'm client."</b>分成三份发送。 <br>
* Hello, <br>
* I'm<br>
* client.<br>
*
* @param e
* Netty事件
* @author lihzh
*/
private void sendMessageByFrame(ChannelStateEvent e) {
String msgOne = "Hello, ";
String msgTwo = "I'm ";
String msgThree = "client.";
e.getChannel().write(tranStr2Buffer(msgOne));
e.getChannel().write(tranStr2Buffer(msgTwo));
e.getChannel().write(tranStr2Buffer(msgThree));
}
/**
* 将字符串转换成{@link ChannelBuffer},私有方法不进行字符串的非空判断。
*
* @param str
* 待转换字符串,要求非null
* @return 转换后的ChannelBuffer
* @author lihzh
*/
private ChannelBuffer tranStr2Buffer(String str) {
ChannelBuffer buffer = ChannelBuffers.buffer(str.length());
buffer.writeBytes(str.getBytes());
return buffer;
}
} |
|
1
2
3
4
|
Hello, I'm clie
nt. |
这里其实,服务端是否分段发送并不会影响输出结果,也就是说,你一次性的把"Hi, I'm client."这段信息发送过来,输出的结果也是一样的。这就是开头说的,传输的是流,不分包。而只在于你如何分段读写。



相关推荐
一个netty的入门教程以及源码分析视频,适合刚学习的人
netty源码解析PDF,网络编程
美团基础架构部闪电侠老师的netty源码分析视频
共分两大章:第1 章:深入浅出Netty源码剖析,第2 章:NIO+Netty5各种RPC架构实战演练,以及课程资料,希望对象学习netty的童靴有用。
Netty源码分析总结.rar
netty源码
netty基本使用以及入门资料,具有netty的源码的分析以及服务器启动过程的介绍
netty源码和相关中文文档。帮助您快速上手netty开发。netty体验之旅祝您愉快
netty源码解析视频教程,深入浅出netty源码视频
Netty好资料,Buffer介绍
Netty源码剖析+视频
Netty5.0架构剖析和源码解读.pdf是一本比较全的讲解netty5的书籍,任何对java的nio技术感兴趣的人都值得一看。
【项目实战】Netty源码剖析&NIO;+Netty5各种RPC架构实战演练三部曲视频教程(未加密)
Netty权威指南源码
netty-3.3.1.Final-sources.jar src源码
Netty源码解读之线程
视频分两部分 第1 章 : 第一部分、深入浅出Netty源码剖析。。 第2 章 : 第二部分、NIO+Netty5各种RPC架构实战演练
netty 源码
netty源码包,可以本地搭建netty源码环境,学习nio模式
Netty源码依赖包,最新版源码依赖包,源码解读必备